assembler 汇编器
把助记符翻译成二进制机器码
assembly language
machine language
LCD (liquid crystal display)
LCD 不是光源而是通过液态水晶控制光的传输
active matrix
动态矩阵显示,使用晶体管(上的电流)精确控制单个像素上光线的传输,使图像更加清晰,在彩色动态矩阵LCD中,还有红-绿-蓝屏决定三种颜色分量的强度,每个像素点需要三个晶体管开关
像素 pixel(px)
picture element
图像由像素矩阵组成,彩色屏幕使用8位表示一个三原色,每个像素用24位表示
px = R(8bit)G(8bit)B(8bit)
IC
Integrated circuit
VLSI
Very-Large-Scale Intergrated circuit
超大规模集成电路
响应时间/执行时间
execution time
吞吐率
带宽 (band-width),单位时间内完成的任务数量
个人PC看重响应时间,服务器注重吞吐率
性能
性能的定义
当我们说一台计算机比另外一台计算机性能好的时候,意味着什么呢?看似简单的问题,但是从不同角度观察得出结果是不同的,书中以客机飞行速度和载客量为例,说明观察角度对结论的影响。
如果是两台不同的桌面计算机运行相同的程序,那么可以说首先完成的速度更快,如果有一个数据中心中有若干台机器用于完成用户提交的作业,那么可以看出一天内完成作业最多的那台计算机更快。
个人计算机(PC)对降低响应时间感兴趣,而数据中心的管理者则对提高吞吐率(带宽)感兴趣。
吞吐率和响应时间
问题:下面两种改进计算机系统的方式能否提高吞吐率或减少响应时间,或二者兼得?
- 将计算机中的处理器替换为更高速的型号。
- 为系统增加额外的处理器,使用多处理器分别处理独立的任务。
答案:一般来说,降低响应时间几乎总是能够提高吞吐率,因此方式1同时改进了响应时间和吞吐率,方式2不会让任务完成的更快,只有吞吐率得到提高,但是假设如果有任务在队列中排队呢?提高吞吐率会减少排队时间,从用户角度看也就是减少了响应时间。
结论:所以在实际的计算机系统中,响应时间和吞吐率往往互相影响
性能:对于计算机X,性能和时间的关系为 P(x) = 1 / E(x)
p = performece
e = exectue time
1 | 如 X 的性能比 Y 好,则 P(X) > P(Y) ==> 1/E(X) > 1/E(Y) ==> E(Y) > E(X) |
性能的度量
时间是计算机性能度量的标准,相同的程序完成时间短的是最快的。
wall clock time or response time or elapsed time
挂钟时间、响应时间、运行时间,这些均表示完成某项任务所需的总时间,包括了磁盘访问、内存访问、I/O 活动和操作系统开销等一切时间。
CPU exception time
计算机经常是被共享的,一个处理器也可能同时运行多个程序,这种情况下系统可能更侧重于优化吞吐率,而不是将单个程序执行时间变短。
在CPU上所花的时间简称 CPU 时间,不包括 I/O 和运行其他程序的时间
user CPU time
用户 CPU 时间,程序本身所花费的时间
system CPU time
为执行程序而花费在操作系统上的时间
有了时间为什么还要周期、频率呢,作为计算机用户关心的是时间,但当我们深入研究计算机细节时,使用其他的度量更方便,几乎所有计算机的构建都需要基于时钟,该时钟确定各类事件在计算机中何时发生,这些离散的时间间隔被称为时钟周期数,clock cycle,设计人员在提及时钟周期时,可能使用完整的时钟周期时间(250皮秒),也可能使用时钟周期的倒数时钟频率。
时钟周期数 (tick、clock tick、clock period、clock、cycle)
滴答数、时钟滴答数、时钟数、周期数为计算机一个时钟周期的时间,通常指处理器时钟,并在固定频率下运行
时钟周期 长度 T(周期)时间单位
每个时钟周期持续的时间长度
那么这个时钟周期(时间)是怎么产生的呢?
CPU 中的时钟周期是由时钟发生器(Clock Generator - A circuit on the motherboard)产生,时钟发生器是计算机中的一个硬件部件,它负责生成周期信号,控制计算机中各个组件的操作步调和同步。
时钟发生器产生的定时信号以恒定的速率进行周期性的震荡,这个震荡的频率决定了 CPU 的频率(主板频率大于等于 CPU 频率),通常以赫兹为单位,如1GHz表示一秒10亿次震荡,时钟频率越高每秒执行的指令越多。
时钟发生器的输出信号通过时钟总线传递给计算机中的各个组件,包括 CPU、内存、输入输出设备等,CPU 内部的电路会根据时钟信号的变化来同步指令执行,确保计算机中的各个部件按照固定的时间步调协调运行。
时钟周期是 CPU 中最小的时间单位,每个时钟周期对应一个操作,一个指令可能包含多个时钟周期。
CPU性能及其度量因素 (减少 CPU 周期数、提高频率(缩短周期长短))
用户和设计者往往使用不同的指标衡量性能,如果可以将这些不同的指标联系起来,就可以确定设计变更对用户可感知的性能的影响。
程序的 CPU 执行时间=程序的 CPU 时钟周期数 * 时钟周期长度(T)
时钟周期长度和时钟频率互为倒数,则 程序的 CPU 执行时间 = 程序的 CPU 时钟周期数/时钟频率
这个公式清晰的表明,硬件设计者减少程序执行所需的 CPU 时钟周期数或缩短时钟周期长度就能改进性能。设计者经常要面对这二者的平衡,许多技术在减少时钟周期数的同时也会增加周期长度。
demo
一个2GHz的计算机A上运行某个程序要10秒,现在需要设计一台计算机B,将运行时间缩短为6秒,硬件设计师承诺能大幅度的提高频率,但会影响其他部分的设计,使得计算机B运行该程序需要相当于A的1.2倍的时钟周期数,问B的频率为多少?
1 | CPU时间A = CPU时钟周期数A/时钟频率A |
指令性能
上面的公式并没有涉及程序所需的指令数,然而,由于编译器明确生成了要执行的指令,且计算机必须通过执行指令来运行程序,因此执行时间必然依赖于程序中的指令数。
公式:CPU时钟周期数 = 程序的指令数 * 指令平均时钟周期数
指令平均时钟周期数 clock cycle per instruction CPI
一条指令所需要的平均时钟周期(机器主频的倒数)数 (指令包含多个周期,求平均值)
根据完成任务的不同,不同的指令需要的时间可能不同,CPI 是程序的所有指令所用时钟周期的平均数
CPI = (总时钟周期数) / (总指令数) CPI提供了一种相同指令系统不同实现下比较性能的方法,因此在指令系统不变的情况下,一个程序执行的指令数是不变的
经典的 CPU 性能公式
CPU 时间 = 指令数 * CPI * 时钟周期长度
CPU 时间 = 指令数 * CPI / 时钟频率
基本的性能指标以及测量单位
| 性能的构成因素 | 测量单位 |
|---|---|
| 程序的 CPU 执行时间 | 程序执行时间,以秒为单位 |
| 指令总数 | 程序执行的指令数目 |
| 指令平均时钟周期数(CPU) | 每条指令平均执行的周期数 |
| 时钟周期长度 | 每个时钟周期长度,以秒为单位 |
时间是唯一对计算机性能进行测量的完整而可靠的指标,CPI与执行指令的类型相关,执行指令数最少的代码未必具有最快的执行速度。
如何确定性能公式中这些因素呢?时间可以通过跑程序算出来,周期长度可以从说明书中的频率得知,难以测量的是指令数和 CPI,根据公式只要知道指令数和 CPI 其一就能算出另外一个。
如何测量指令数和 CPI 呢?可以用体系结构仿真器等软件工具或大多数处理器中的硬件计数器来测量指令数、平均 CPI (还有性能损失源)。由于指令数取决于计算机体系结构,并不依赖于计算机的具体实现,因此可以在不知道计算机全部实现细节的情况下对指令数进行测量,但是 CPI 与计算机的各个设计细节密切相关,包括存储系统和处理器结构,以及应用程序中不同类型的指令所占的比例,因此,CPI 对于不同的应用程序是不同的,对于相同指令系统的不同实现方式也是不同的。
上述表明,只用一种因素(如指令数)去评价性能是危险的,当比较两台计算机时必须考虑全部三个因素,它们组合起来才能确定执行时间。
CPI 根据指令分布的不同而变化。
理解程序性能
程序的性能与算法、编程语言、编译器、体系结构以及实际的硬件有关。
| 硬件或软件指标 | 影响 | 如何影响 |
|---|---|---|
| 算法 | 指令数、CPI | 算法决定源程序执行指令的数目,从而决定 CPU 执行指令的数目,算法也可能通过使用较快或较慢的指令影响 CPI,比如当算法使用更多的除法运算时,将会导致 CPI 增大 |
| 编程语言 | 指令数、CPI | 编程语言显然会影响指令数,因为编程语言中的语句必须翻译为指令,从而决定了指令数,编程语言也可影响 CPI,比如 JAVA 语言充分支持数据抽象,因此将进行间接调用,需要使用 CPI 较高的指令 |
| 编译器 | 指令数、CPI | 因为编译器决定了源程序到计算机指令的翻译过程,所以编译器的效率影响指令数又影响 CPI,编译器的角色十分复杂,并以多种方式影响 CPI |
| 指令系统体系结构 | 指令数、CPI、时钟频率 | 指令系统体系结构影响 CPU 性能的所有三方面,因为它影响完成某功能所需的指令数、每条指令的周期数以及处理器的时钟频率 |
IPC (Instruction Per Clock Cycle)
有些处理器在每个时钟周期可对多条指令取指并执行,有些设计者用 IPC 来代替 指令平均执行周期数 CPI。
如一个处理器每个时钟周期平均可执行2条指令,则它的 IPC = 2,CPI = 0.5
虽然时钟周期长度传统上是固定的,但为了节省能量或暂时提升性能,当今的计算机可以使用不同的时钟频率,因此我们需要对程序使用平均时钟频率,例如,Intel Core i7 处理器在过热之前可以暂时将时钟频率提高10%,Intel 称之为快速模式(Turbo mode)
功耗墙
功
1 | w = F * S (N*m) |
功 = 力乘力的方向上物体移动的距离(力的单位是牛顿N,距离的单位是米,功的单位是牛米、焦耳)
功率
功率表示做功的快慢。功与做功时间之比,叫做功率。功率的表达式为:P=W/t,其中,W为功,t为做功的时间,P为功率。
功率P的国际单位制是瓦特,符号是W。工程上往往还用千瓦(kW)作为功率的单位。1瓦特=1焦/秒,即1W=1J/s。
功耗
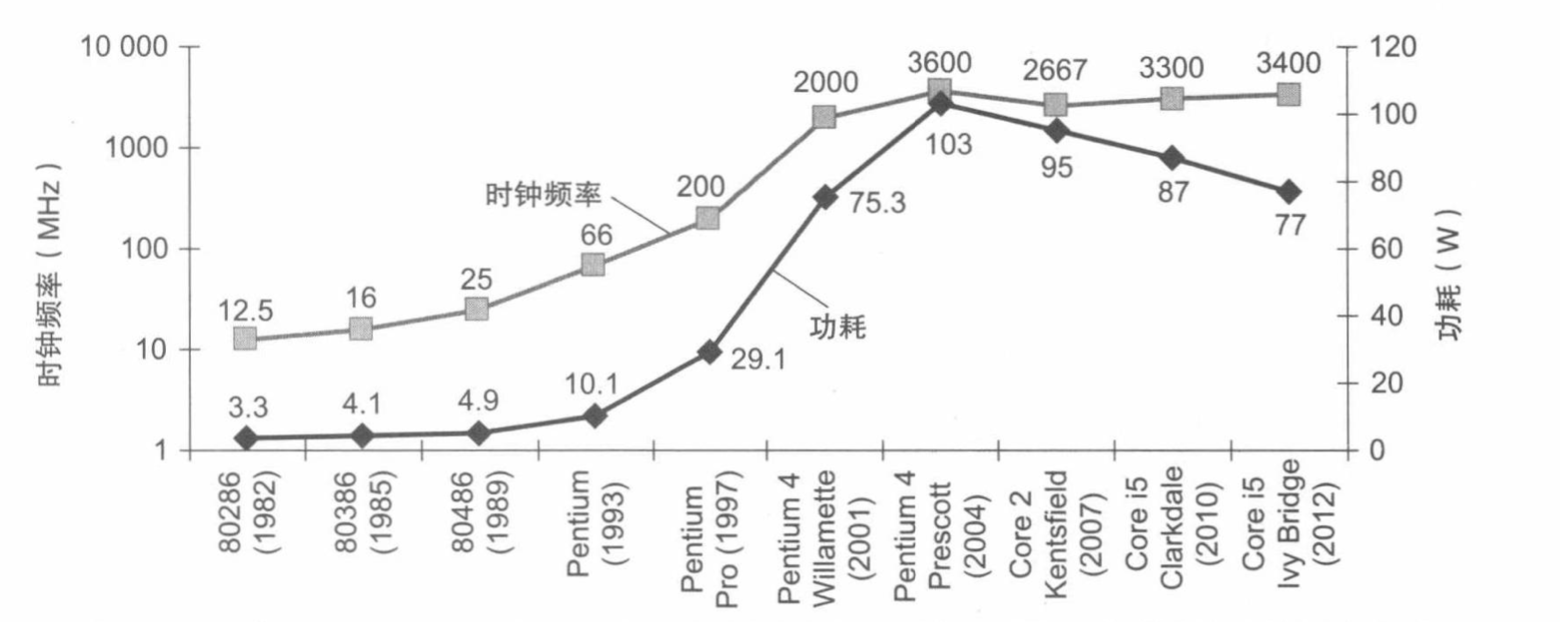
功耗在不同的语境下意思不同。这里代表功率。
动态功耗
芯片在工作时晶体管处于跳变状态所产生的功耗,称为动态功耗。
1 | 在CMOS集成电路中 |
思考一下,为什么时钟频率增长了1000倍,而功耗只增长了30倍呢?因为功率是电压平方的函数,功率和能耗能够通过降低电压来大幅减少,每次工艺更新换代时都会这样,一般来说,每次技术更新换代可以使得电压降低大约15%,20多年来,电压从5V降到了1V,这就是功耗只增长30倍的原因。
目前的问题是如果继续下降电压会使晶体管的泄露电流过大,目前40%的功耗是由于泄露电流造成的,如果泄露电流进一步增大,情况更难处理。
为了解决功耗问题,设计者尝试连接大型设备改善冷却效果,同时关闭芯片中在给定时钟周期内暂时不用的部分。尽管有很多昂贵的方式来冷却芯片,可以继续将芯片的功耗提升到300W的水平,但对于个人计算机甚至服务器来说成本太高了。
由于计算机设计者遇到功耗墙问题,必须开辟新的路径,选择不同于30年来设计微处理器的方式。
虽然动态能耗是CMOS能耗的主要来源,但静态能耗也是存在的,即使晶体管关闭的情况下,也有泄露电流存在,在服务器中典型的电流泄露占40%的能耗,因此,只要增加晶体管的数目,即使这些晶体管总是关闭的,也仍然会增加漏电能耗,人们采用各种各样的设计和工艺创新来控制电流泄露,但还是难以进一步降低电压。
功耗成为集成电路设计的挑战有两个原因:1. 电源必须由外部输入并分到芯片的各个角落。现代微处理器通常使用几百个引脚作为电源和地线。2. 散热问题
沧海巨变:单处理器到多处理器
功耗的极限迫使微处理器的设计产生巨变,从2006年所有的桌面和服务器公司都在单个微处理器中加入了多个处理器,以求更大的吞吐率,而不在继续追求降低单个程序运行在单个处理器上的响应时间。
在过去,程序员可以依赖于硬件、体系结构和编译器的创新,无须修改一行代码,就能实现程序的性能每18个月翻一番,而今天程序员要想显著改善响应时间,必须重写程序以充分利用多处理器的优势。
并行编程对程序员是个挑战,需要考虑很多因素,任务的切分、调度、同步、正确性等等。
SPEC - Standard Performance Evaluation Corporation
基准测试
谬误与陷阱
陷阱: 在改进计算机的某个方面时期望总性能的提高与改进大小成正比
amdahl定律 边际收益递减定律
1 | 改进后的执行时间 = 受影响的执行时间/改进量 + 不受影响的执行时间 |
比如一个程序运行要100秒,其中80秒用于乘法计算,如果要把程序运行速度提升5倍,乘法操作的速率应该改进多少?
1 | 改后的时间 = 80/n + (100-80),由于要求快5倍,新的执行时间应该是20,则 |
也就是说,如果乘法运算占比总负载的80%,则无论怎样改进乘法,也无法达到性能提升5倍的结果,针对特定情况的提升受到被改进的特征所占比例的限制,这个概念在日常生活中被称为边际收益递减定律。
谬误:低利用率的计算机具有更低的功耗
比如服务器的工作负载是变化的,低利用率的情况下的功率很重要。谷歌服务器利用率大多在10%-50%之间,只有不到1%的时间达到100%的利用率。即使在最优配置的电脑中,跑SPECpower程序,10%的工作负载也会使用33%的峰值功耗,实际工作中的系统可能更糟糕。
谬误:面向性能的设计和面向能效的设计具有不相关的目标
由于能耗是功率和时间的乘积,在通常情况下,对于软硬件的性能优化而言,即使优化需要更多的能耗,但是这些优化缩短了系统运行时间,因此整体上也还是节约了能量,一个重要的原因在于只要程序运行,计算机的其他部分就会消耗能量,因此即使优化的部分多消耗一些能量,运行时间缩短也可以降低整个系统的能耗。
陷阱:用性能公式的一个子集去度量性能
之前指出过只用时钟频率、指令数和 CPI 之一来预测性能的不足,而另一种常犯的错误是只用三种因素之二去比较性能,虽然这样做在有些限定场景下可能正确,但会被误用。
比如 MIPS 每秒每百万指令数衡量尺度,这种方法存在三个问题:
- MIPS 规定了指令执行的速率,但没考虑指令的能力
- 同一台计算机上,不同的程序会有不同的 MIPS,因而一台计算机不能拥有单一的 MIPS 分值
- 如果一个新程序执行的指令数更多,但每条指令的执行速度更快,则 MIPS 可能独立于性能而发生变化
注意:执行时间是唯一有效且不可推翻的性能度量指标