概要
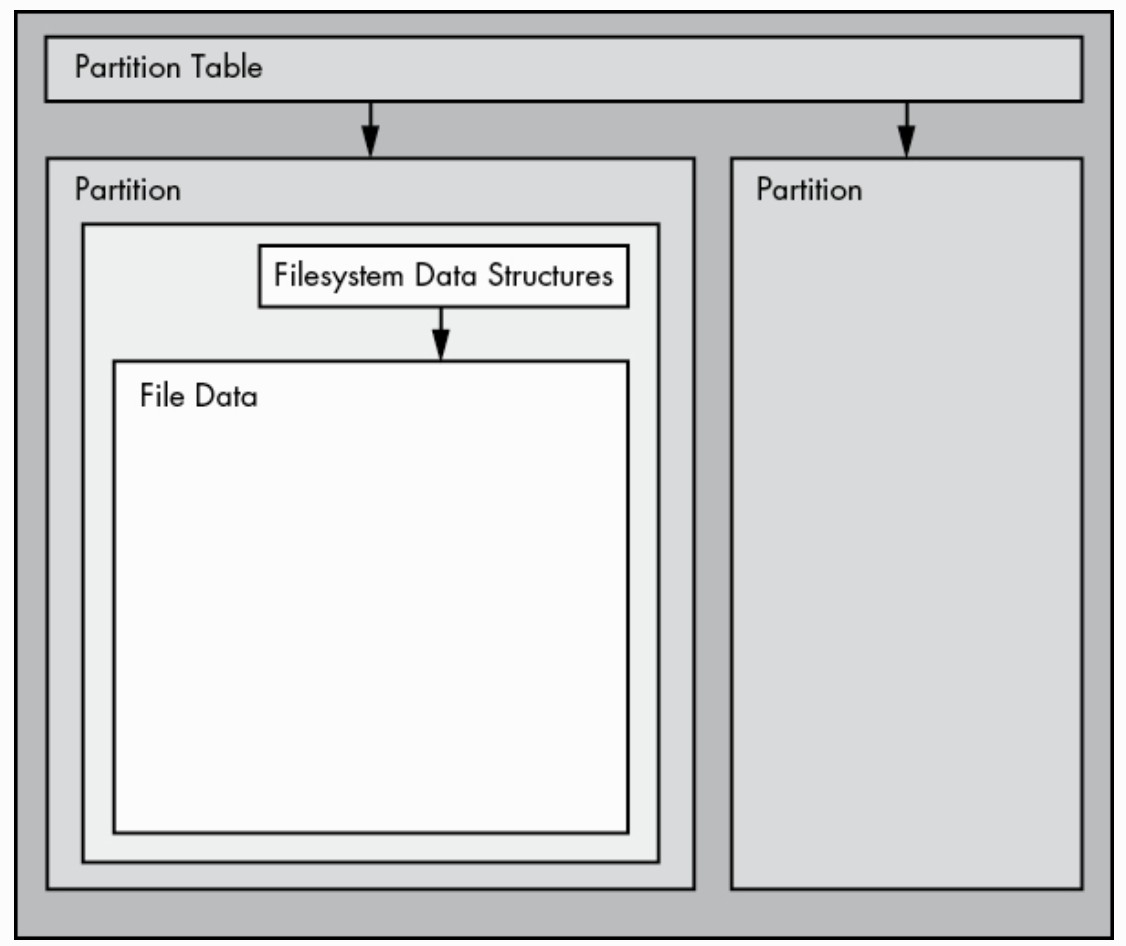
分区是整个磁盘的细分。在 Linux 上,它们在整个块设备后面用数字表示,因此它们的名称类似于 /dev/sda1 和 /dev/sdb3。内核将每个分区呈现为块设备,就像整个磁盘一样。分区是在磁盘的一个小区域上定义的,称为分区表(也称为磁盘标签)。是否要分区根据实际情况定,最好把系统放到一个单独的分区上,方便后续的升级。
如图所示,要想读取某个文件中的数据,we need to use the appropriate partition location from the partition table and then search the filesystem database on that partition for the desired file data。即先分区在找到那个分区上的文件系统。
Partitioning Disk Devices
有很多类型的分区表,关于分区表并没有什么特殊地方,它仅仅是一些数据描述了磁盘上的 blocks 是如何划分的。
传统的表可以追溯到 PC 时代,是在主引导记录 Master Boot Record (MBR) 中找到的表,它有很多限制。大多数较新的系统都使用全局唯一标识符分区表 Globally Unique Identifier Partition Table(GPT)。
下面是一些 Linux 分区工具:
- parted partition editor 支持 MBR 和 GPT 的基于文本的分区工具
- gparted parted 的图形化界面版本
- fdisk 文本的命令行工具,支持 MBR 和 GPT
fdisk 是交互式的,在真正变更前,不会对系统进行更改。
分区和文件系统操作之间存在一个关键区别:分区表定义了磁盘上的简单边界,而文件系统是一个复杂得多的数据系统。因此,要使用单独的工具来分区和创建文件系统。
查看一个分区表
parted -l 或者 fdisk -l 查看分区表。
1 | Model: Virtio Block Device (virtblk) |
MBR 分区表
MBR 分区表,包括 priamry、extended 和 logical 分区,主分区就是普通的磁盘上的分区。MBR 只支持 4 个主分区,如果想要更多的分区,就要把其中的一个主分区设计为扩展分区,在扩展分区内划分逻辑分区。
修改分区表 Modifying Partition Tables
查看分区表很简单而且对系统来说是无害的操作,修改分区表也相对容易但是存在一些风险:
- 更改分区表使得恢复删除或重新定义的分区上的任何数据变得非常困难,因为这样做可能会擦除这些分区上文件系统的位置。如果要分区的磁盘包含关键数据,请确保有备份
- 确保目标磁盘上没有正在使用的分区,这是一个担忧点,因为大多数 Linux 发行版会自动挂载侦测到的文件系统
准备好后,选择分区工具,一般有 parted 和 fdisk 两个工具,前者会实时更新,后者会在退出程序时实施分区。
这些不同之处是理解两个工具是如何和内核交互的关键,两个都是在用户空间修改分区的,不需要内核提供支持来重新分区表,因为用户空间能读写所有的块设备。
不过,在某些时候,内核必须读取分区表,以便将分区呈现为块设备,以便可以使用它们。fdisk使用一个相对简单的方式,在修改分区表后,fdisk发起一个 sys call 来告诉内核要重新读取某个磁盘上的分区表,然后内核会输出一些 debugging 信息,可以使用 journalctl -k 查看。
而 parted 工具并不使用这个整个磁盘级别的 sys call,相反,当单个分区修改了它向内核发送信号,内核在处理完分区修改后,并不会产生调试信息,有以下几种方法能查看分区的修改操作:
- 使用
udevadm观察内核事件的改变 - 检查
/proc/partitions文件,查看所有分区信息 - 检查
/sys/block/device/或者/dev
分区表和磁盘的关系
- 一个物理磁盘会有一个分区表,它描述磁盘上的所有分区情况,一对一
- 但是,分区表可以管理多个分区,因此这是一对多的关系
强制重新加载分区表
如何想非常确定修改的分区表得到应用,可以使用 blockdev 来发起一个 old-style sys call (就像 fdisk 使用的 sys call),比如要强制内核 reload 在 /dev/sdf 上的分区表,可以用 blockdev --rereadpt /dev/sdf。
创建一个分区表
fdisk创建分区表
创建分区表后,就要在分区上放置文件系统了。
磁盘结构
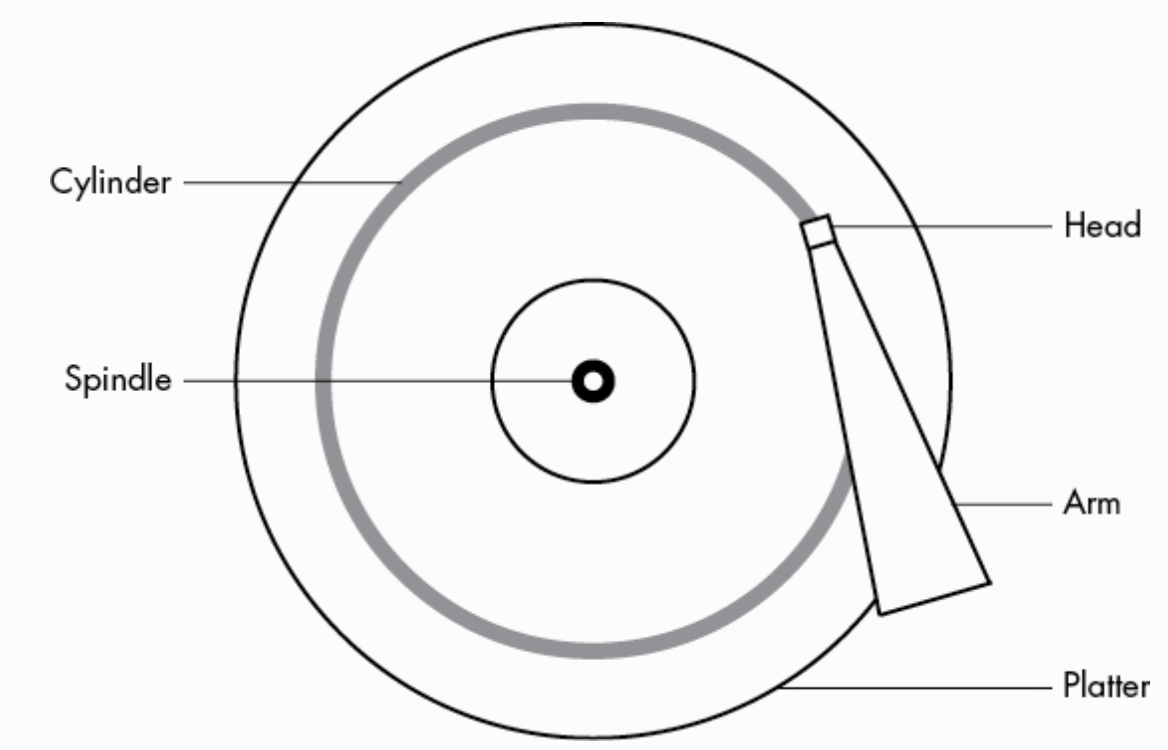
- Cylinder 柱面
- Spindle 主轴
- Head 磁头
- Arm 机械壁
- Platter 盘片
- tracks 磁道
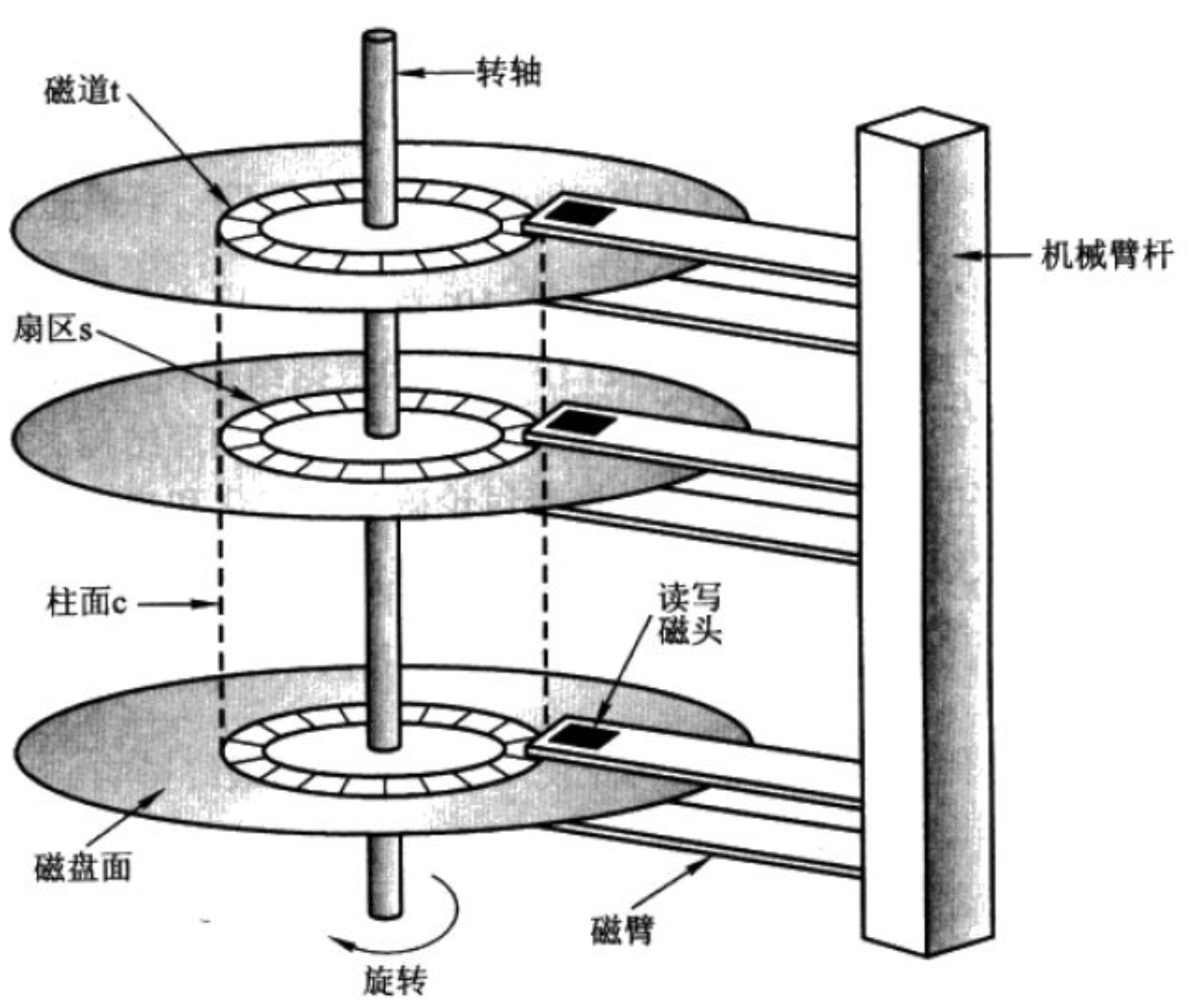
硬盘中一般会有多个盘片组成,每个盘片包含两个面,每个盘面都对应地有一个读/写磁头。受到硬盘整体体积和生产成本的限制,盘片数量都受到限制,一般都在5片以内。盘片的编号自下向上从0开始,如最下边的盘片有0面和1面,再上一个盘片就编号为2面和3面。
下图显示的是一个盘面,盘面中一圈圈灰色同心圆为一条条磁道,从圆心向外画直线,可以将磁道划分为若干个弧段,每个磁道上一个弧段被称之为一个扇区(绿色部分)。扇区是磁盘的最小组成单元,通常是 512 字节。(由于不断提高磁盘的大小,部分厂商设定每个扇区的大小是4096字节)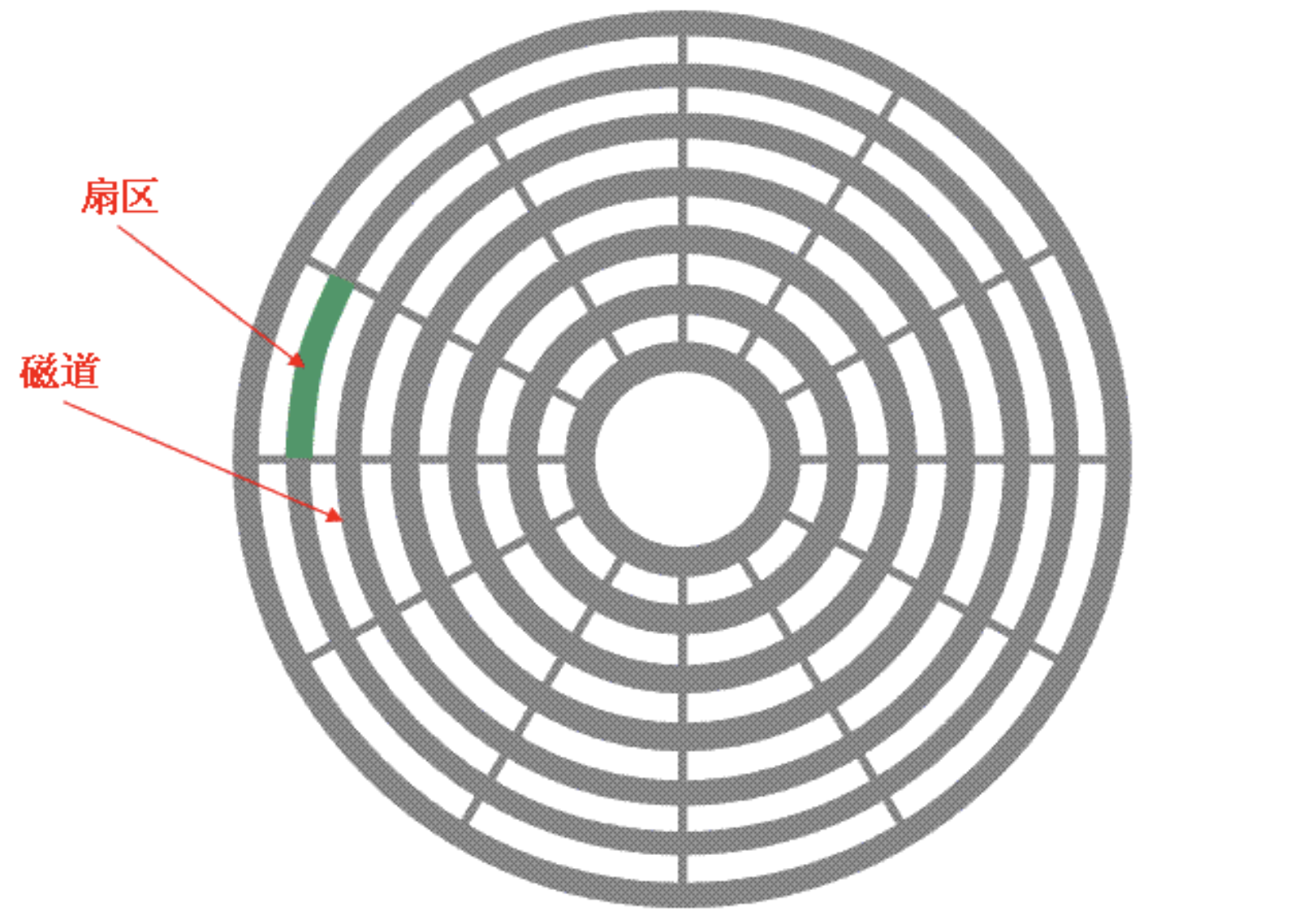
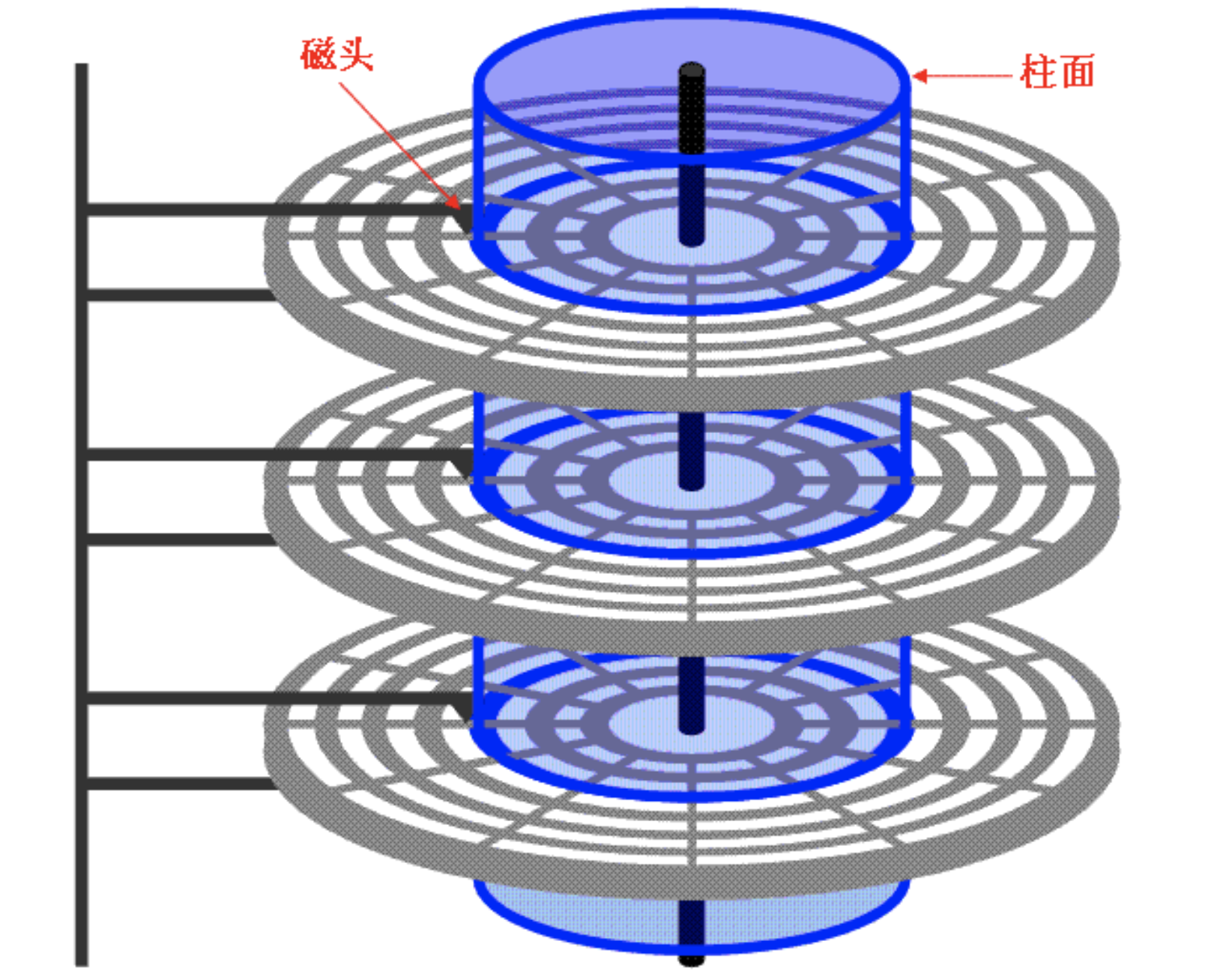
硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的“0”开始编号,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面。磁盘的柱面数与一个盘面上的磁道数是相等的。由于每个盘面都有自己的磁头,因此,盘面数等于总的磁头数。
存储容量 = 磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
块/簇
磁盘块/簇(虚拟出来的)。块是操作系统中最小的逻辑存储单位。操作系统与磁盘打交道的最小单位是磁盘块。
通俗的来讲,在 Windows 下如 NTFS 等文件系统中叫做簇;在 Linux 下如 Ext4 等文件系统中叫做块(block)。每个簇或者块可以包括2、4、8、16、32、64…2的n次方个扇区。
为什么要有磁盘块
读取方便,由于扇区的数量比较小、数目众多在寻址时比较困难,所以操作系统就将相邻的扇区组合在一起,形成一个块,在对块进行整体的操作。
分离对底层的依赖,操作系统忽略对底层物理存储结构的设计,通过虚拟出来的磁盘块的概念,在系统中认为块是最小的单位。
page
操作系统经常与内存和硬盘这两种存储设备进行通信,类似于“块”的概念,都需要一种虚拟的基本单位。所以,与内存操作,是虚拟一个页的概念来作为最小单位。与硬盘打交道,就是以块为最小单位。
扇区、块/簇、page的关系
- 扇区:硬盘的最小读写单元
- 块/簇:是操作系统针对硬盘读写的最小单元
- page:是内存与操作系统之间操作的最小单元
CHS cylinder-head-sector
CHS(Cylinder-Head-Sector)是一种用于描述磁盘地址的方式,它代表磁盘的物理几何结构。CHS 模型通过柱面(Cylinder)、磁头(Head)和扇区(Sector)的组合来确定磁盘上存储数据的具体位置。在早期计算机中,磁盘地址使用 CHS 来寻址。
CHS 的工作方式
CHS 将磁盘的物理空间分为若干个柱面,每个柱面上有多个磁头,每个磁头下有多个扇区。因此,一个 CHS 地址可以唯一标识磁盘上的一个物理数据块。
CHS 的限制
磁盘容量的限制:由于 CHS 寻址方式使用的是较小的数字范围来表示柱面、磁头和扇区的数量,传统的 CHS 寻址方式存在容量限制。例如,早期的 BIOS 仅支持 1024 个柱面、255 个磁头、63 个扇区的寻址限制,总容量大约是 8.4 GB。
取代:随着磁盘容量的增大,CHS 已不再适用于现代磁盘,现在普遍使用的是 LBA(Logical Block Addressing,逻辑块地址)来替代 CHS。LBA 通过一个线性的编号来表示磁盘上的数据块,无需考虑磁盘的物理结构。
总结来说,CHS 是一种旧式的磁盘寻址方式,适用于较小容量的磁盘,但由于其局限性,已被更灵活的 LBA 所取代。
分区分好后就需要安装文件系统了。
文件系统
之前提过,文件系统其实就是某种形式的数据结构,它以结构的方式把块设备转换成用户能理解的目录、文件层次结构。
曾经,所有文件系统都驻留在专门用于数据存储的磁盘和其他物理介质上。然而,文件系统的树状目录结构和 I/O 接口非常通用,因此文件系统现在执行各种任务,例如在 /sys 和 /proc 中看到的系统接口,这些是基于内存的。文件系统从传统上是在内核中实现的,但是也有在用户空间的文件系统,The File System in User Space FUSE。
虚拟文件系统(VFS)抽象层完成了文件系统的实现。就像 SCSI 子系统标准化不同设备类型和内核控制命令之间的通信一样,VFS 确保所有文件系统实现都支持标准接口,以便用户空间应用程序以相同的方式访问文件和目录。 VFS 支持使 Linux 能够支持数量异常庞大的文件系统。
文件系统是独立于内核的吗?
文件系统通常并不是完全独立于内核的。事实上,文件系统与内核紧密耦合,因为它需要通过内核提供的接口来管理和访问存储设备上的数据。然而,文件系统和内核确实有一定程度的分离,以便能够支持多种文件系统类型。
内核与文件系统的关系
- 内核空间与用户空间:文件系统通常位于内核空间,这意味着它们运行在高权限的内核模式下,而不是在低权限的用户模式下。内核提供对硬件设备的直接访问,文件系统通过内核的API与底层存储设备(如硬盘、SSD)交互。
- 文件系统驱动:内核中包含文件系统驱动(如ext4、NTFS、FAT等),这些驱动定义了文件系统如何组织、存储和检索数据。当应用程序在用户空间发出文件操作请求时,内核通过这些驱动将请求转发给文件系统,以执行相应的操作。
- 虚拟文件系统 (VFS):VFS 是内核的一部分,它为不同类型的文件系统提供了一个抽象层。VFS 允许应用程序以统一的方式访问不同的文件系统,而无需关心底层实现的差异。VFS 将应用程序的请求映射到实际的文件系统驱动上,从而进行具体的操作。
文件系统与内核的分离程度:
虽然文件系统依赖于内核提供的服务和接口,但不同的文件系统可以在相同的内核上运行。这意味着,内核能够通过不同的文件系统驱动来支持多种文件系统格式,而不需要修改应用程序或重构内核本身。这种设计提高了文件系统的灵活性和可扩展性。
因此,虽然文件系统与内核密切相关,但它们通过 VFS 和文件系统驱动等机制实现了一定程度的分离,允许内核支持多种不同的文件系统。
文件系统的数据在哪里?
文件系统的数据主要存储在计算机的物理存储设备上,如硬盘驱动器 (HDD)、固态硬盘 (SSD)、光盘、闪存等。文件系统的任务是管理这些数据,并提供一个结构化的方式来存取它们。具体来说,文件系统的数据包括以下几个部分:
- 用户数据:这是文件系统中用户实际存储的文件内容,如文档、图片、视频、数据库文件等。用户数据被存储在存储设备的数据块中。
- 元数据:元数据是描述文件和目录的结构和属性的信息。例如:
- 文件名:文件系统中的每个文件和目录都有一个唯一的名称。
- 文件大小:文件的实际大小,以字节为单位。
- 文件权限:定义谁可以读取、写入或执行该文件。
- 时间戳:文件的创建、修改和访问时间。
- 文件指针:指向存储用户数据的数据块。
对于一个分区的磁盘,每个分区都有一个文件系统吗
是的,对于一个磁盘上的每个分区,通常都会有一个独立的文件系统。每个分区可以被格式化为不同的文件系统类型,并且这些文件系统独立管理分区中的数据。
磁盘分区
磁盘分区是将物理磁盘划分为多个独立的区域,每个区域称为一个分区。分区使得一个磁盘可以被多个操作系统或文件系统共享。
常见的分区类型有主分区、扩展分区和逻辑分区。
文件系统的作用
每个分区通常会被格式化为一个特定的文件系统,如 ext4、NTFS、FAT32、HFS+ 等。文件系统负责管理分区中的数据,包括文件和目录的组织、存储和检索。
独立性
磁盘上的每个分区都可以拥有独立的文件系统。这意味着即使在同一个物理磁盘上,不同的分区可以使用不同的文件系统。例如,一个分区可以使用 ext4 文件系统(常用于Linux),而另一个分区可以使用 NTFS 文件系统(常用于Windows)。
多操作系统支持
这种分区与文件系统的独立性允许一个磁盘同时支持多个操作系统。例如,一个磁盘可以有一个分区用于 Linux(ext4文件系统),另一个分区用于Windows(NTFS文件系统),它们可以共存而互不影响。
对于一个分区的磁盘,通常每个分区都有自己的文件系统,负责管理该分区内的数据。这种设计提高了灵活性,使得同一磁盘可以使用多种文件系统类型。
到底要不要对磁盘进行分区
是否要对磁盘进行分区取决于具体需求和使用场景。分区有其优点,但在某些情况下也可能不必要或带来复杂性。
以下是对磁盘进行分区的优缺点,以及在不同情况下的建议。
分区的优点
- 多操作系统支持:如果需要在同一台计算机上安装多个操作系统,分区是必要的。每个操作系统可以安装在单独的分区上,互不干扰。
- 数据隔离:分区可以用于将系统文件和用户数据分开存储。这样,即使系统崩溃或需要重装,用户数据仍然保存在其他分区中,减少数据丢失的风险。
- 提高管理效率:将不同类型的数据放在不同的分区上(如系统、数据、备份等),可以帮助更好地管理和组织数据。例如,可以将系统分区设置得较小以便于备份和恢复,而将数据分区设置得较大以存储大量文件。
- 性能优化:在某些情况下,不同分区可以使用不同的文件系统或设置不同的参数,从而优化性能。例如,日志文件可以存放在一个分区,用户数据存放在另一个分区,以减少碎片化和提高访问速度。
分区的缺点
- 灵活性降低:一旦分区的大小确定,调整可能会很复杂。如果某个分区空间不足,而另一个分区还有大量空闲空间,重新分配这些空间可能需要专门的工具和时间。
- 潜在的浪费:不合理的分区规划可能导致某些分区空间用不完,而其他分区空间不足,导致存储空间的浪费。
- 管理复杂性:多个分区意味着需要管理更多的文件系统和挂载点,增加了维护的复杂性。对于不熟悉分区管理的用户,这可能是一个挑战。
什么时候应该分区:
- 安装多个操作系统:需要在同一台计算机上运行不同的操作系统。
- 数据隔离需求:希望将系统和数据分开,以便于管理和保护数据。
- 特定性能需求:需要为不同用途优化性能,例如为数据库、日志文件、或者虚拟内存单独分区。
- 备份需求:希望简化备份和恢复过程,例如只备份系统分区。
什么时候不必分区:
- 单一操作系统:如果只使用一个操作系统,并且没有特殊的数据隔离需求,单一分区通常是更简单的选择。
- 灵活性优先:希望系统能够自由分配磁盘空间,不想被固定的分区大小限制。
- 易用性:希望避免管理多个分区的复杂性。
总结
对磁盘进行分区有其优点,尤其是在需要多操作系统支持、数据隔离或性能优化的情况下。但如果你的需求相对简单,且希望保持系统的灵活性和易用性,那么不进行分区或仅进行简单的分区可能是更好的选择。
一个磁盘上的分区表只有一个,分区会有多个,文件系统也会有多个。
文件系统在每个分区内吗
是的,文件系统通常是在每个分区内存在并运行的。每个分区可以被格式化为不同类型的文件系统,文件系统负责管理该分区中的数据,如文件、目录、权限、时间戳等。
分区和文件系统的关系
一个物理磁盘可以被划分为多个分区。每个分区是一个独立的存储区域,并且可以被格式化为一个文件系统类型,如ext4、NTFS、FAT32等。
文件系统是分区的逻辑结构,它决定了如何在分区内存储和管理数据。
格式化
当格式化一个分区时,实际上是在该分区上创建一个新的文件系统。这会清空分区中的所有数据,并在其中建立文件系统的元数据结构,以便存储文件和目录。
挂载点
操作系统通过挂载文件系统来访问分区内的数据。挂载点是文件系统在操作系统中的入口,通常是一个目录(例如 /mnt/data 或 C:\),分区内的数据通过该目录进行访问。
独立性
每个分区的文件系统是独立的,可以使用不同的文件系统类型。例如,磁盘的一个分区可以使用ext4文件系统(通常用于Linux),另一个分区可以使用NTFS文件系统(通常用于Windows)。它们之间互不影响。
总结
文件系统是存在于每个分区内的,负责管理该分区中的数据。每个分区通常都有自己的文件系统,这些文件系统可以是同一种类型,也可以是不同类型,具体取决于系统的配置和使用需求。
分区表在哪里
分区表(Partition Table)是存储设备(如硬盘或SSD)上用于描述分区信息的一个数据结构。它通常位于磁盘的开头部分,用于记录每个分区的起始位置、大小和类型等关键信息。
具体位置
主引导记录(MBR)位置:对于使用传统MBR(Master Boot Record)分区表的磁盘,分区表位于磁盘的第一个扇区,即LBA 0(逻辑块地址0)。
结构:MBR的大小是 512 字节,其中前 446 字节通常用于存储引导程序代码,接下来的64字节用于存储分区表,最后的2字节是标志符。
分区限制:MBR分区表最多支持4个主分区。如果需要更多分区,可以创建扩展分区,并在其中包含逻辑分区。
GUID分区表(GPT):对于使用GPT(GUID Partition Table)分区表的磁盘,分区表的主要副本位于磁盘的第一个扇区之后,通常是第一个扇区到第33个扇区之间。同时,GPT在磁盘的末尾也保存了一份备份分区表,用于冗余和恢复。
结构:GPT使用全球唯一标识符(GUID)来标识分区,支持更大的分区数量和容量。GPT的首个扇区称为保护MBR(Protective MBR),用于兼容传统系统,但实际分区信息存储在后续的扇区中。
分区优势:GPT可以支持多达128个分区(甚至更多,取决于操作系统和工具),且每个分区的大小限制远高于MBR。
分区表的作用
- 描述分区信息:分区表详细记录了每个分区的起始和结束位置、类型标识符(例如文件系统类型)等信息,使操作系统能够识别并访问磁盘上的各个分区。
- 加载引导程序:对于MBR分区表,MBR还包含用于加载操作系统引导程序的代码。当计算机启动时,BIOS/UEFI首先读取MBR中的代码,并根据分区表信息加载操作系统。
总结
分区表位于磁盘的开头部分,对于MBR分区表,通常在第一个扇区(LBA 0),而对于GPT分区表,主要表位于磁盘的前几个扇区,并且在磁盘末尾保留了备份。分区表是管理磁盘分区的关键数据结构,使操作系统能够识别并管理磁盘上的分区。
文件系统一般多大
想问文件系统所占元数据的大小,但回答的不是。
文件系统的大小通常与其所在的磁盘分区的大小相同。文件系统占据整个分区的空间,大小由你在创建分区时指定。因此,文件系统的大小可以变化很大,从几个MB到TB不等,取决于分区的大小和磁盘的容量。
影响文件系统大小的因素
- 分区大小:文件系统的大小由分区大小决定。创建分区时,指定了分区的大小,而文件系统会占用整个分区空间。因此,如果分区是 100 GB,那么文件系统也将是 100 GB。
- 文件系统类型:不同的文件系统类型可能在存储相同数据时需要不同的开销。一些文件系统在管理元数据(如文件名、权限、时间戳等)时会使用更多的空间。这种开销通常是很小的,但对于非常大的分区和大量的文件,可能会有影响。
- 一些文件系统类型可能支持特定的压缩或去重功能,从而影响数据的实际存储大小。
- 磁盘块大小:文件系统将分区空间划分为较小的块(通常是4 KB、8 KB等)。较大的块大小可能导致空间浪费,特别是在大量小文件的情况下,因为每个文件至少会占用一个块的大小,即使它比块小很多。
- 元数据和日志空间:一些文件系统(如ext4、XFS、ZFS等)会为日志文件、元数据存储和其他系统功能保留一定的空间。这些区域的大小也会影响可用的用户数据空间,但一般来说,这部分开销在整个文件系统中占的比例较小。
文件系统的实际大小与可用空间
- 可用空间:文件系统的总大小与可用空间是不同的。总大小是文件系统的分区大小,而可用空间是用户可用来存储文件的空间。可用空间一般小于总大小,因为一部分空间被用来存储文件系统的元数据、日志文件等系统数据。
总结
文件系统的大小通常等于其所在分区的大小,可能是从几个MB到TB不等。
实际可用空间会略小于分区大小,因为文件系统会为元数据、日志和其他系统功能保留一部分空间。
选择合适的分区大小和文件系统类型,确保它们适应存储需求和性能要求。
文件系统的元数据一般多大
文件系统的元数据大小是由文件系统类型、所存储文件的数量和分区大小等多种因素决定的。元数据通常占用文件系统的一部分空间,用于存储文件的属性信息,如文件名、权限、时间戳、文件大小、数据块位置等。尽管元数据对于整个文件系统来说可能只占用很小的一部分,但它对文件系统的性能和功能有很大影响。
元数据的组成和大小
索引节点 (inode)
- 作用:索引节点是大多数文件系统(如ext4、XFS等)用于存储单个文件元数据的结构。每个文件和目录都有一个 inode,里面包含了文件的基本信息(不包括文件名)。
- 大小:每个 inode 的大小通常是固定的,例如,ext4文件系统的inode大小通常为128字节到512字节不等。每个文件或目录都占用一个inode。
目录结构
- 作用:目录结构是文件系统用于管理文件名及其与inode的关联关系的元数据部分。
- 大小:目录结构的大小取决于文件系统类型和目录中包含的文件数量。例如,对于ext4,目录项通常占用数十字节。
超级块 (Superblock)
- 作用:超级块包含文件系统的全局信息,如文件系统的大小、块大小、空闲块数量、inode数量等。它是文件系统启动和管理的关键部分。
- 大小:超级块通常很小,一般只有几个KB。
块位图和inode位图
- 作用:这些位图用于跟踪哪些数据块和inode是空闲的,哪些是已使用的。
- 大小:位图的大小取决于文件系统的大小和块的数量。通常,占用空间较小,但在非常大的文件系统中可能会占用几MB。
日志文件 (Journal)
- 作用:用于日志记录以支持文件系统的事务处理(如ext3、ext4、XFS等的日志文件系统)。它在系统崩溃时帮助恢复数据一致性。
- 大小:日志文件通常占用几MB到几GB的空间,取决于文件系统的配置。
总体元数据占用空间
百分比估算:元数据通常占用文件系统总空间的1-5%。例如,ext4文件系统在默认配置下,通常保留5%左右的空间用于inode和其他元数据,这在普通用途下已经足够容纳大量文件。
绝对大小:在一个1 TB的分区上,元数据可能占用数GB的空间,但实际大小会随文件系统的类型、配置和分区的使用情况而变化。
影响元数据大小的因素
- 文件数量:文件系统上文件和目录的数量直接影响元数据的总大小。更多的文件需要更多的inode和目录结构。
- 块大小:较小的块大小会导致需要更多的元数据来跟踪文件数据,但也可能减少空间浪费。
- 日志功能:使用日志文件系统时,日志文件的大小配置会影响元数据的总大小。
总结
文件系统的元数据通常只占文件系统总空间的一小部分,一般在1-5%左右,具体大小取决于文件系统类型、文件数量、块大小等因素。实际的元数据大小可以从几MB到数GB不等,尤其是在大型文件系统中。
分区表和文件系统是不同的东西吗
是的,分区表和文件系统是不同的东西,它们在磁盘存储管理中扮演着不同的角色。
分区表 (Partition Table)
- 作用: 分区表是一种数据结构,位于磁盘的开头,用于描述磁盘上各个分区的布局和信息。它包含每个分区的起始位置、大小、类型等信息。
- 位置: 分区表通常位于磁盘的第一个扇区。对于使用MBR(Master Boot Record)的磁盘,分区表位于第一个扇区的特定位置。对于使用GPT(GUID Partition Table)的磁盘,分区表分布在磁盘的开头和末尾部分。
- 内容: 分区表主要记录磁盘上每个分区的详细信息,如起始位置、结束位置、分区类型(例如,主分区、扩展分区、逻辑分区),以及该分区是否可引导等信息。
- 作用: 分区表的主要功能是告知操作系统磁盘上有哪些分区,以及这些分区的物理位置,以便系统能够正确访问和管理这些分区。
文件系统 (File System)
- 作用: 文件系统是在一个分区内用来组织、存储和管理文件及数据的一种结构。文件系统决定了如何在磁盘上存储数据、如何访问文件和目录、如何管理文件权限和元数据等。
- 位置: 文件系统位于磁盘分区内部。当将一个分区格式化为某种文件系统类型(如ext4、NTFS、FAT32等)时,文件系统会占据该分区的全部空间。
- 内容: 文件系统包含多个组成部分,包括数据块、索引节点(inode)、目录结构、超级块等,用于存储文件内容及其相关的元数据。
- 作用: 文件系统的主要功能是管理分区中的数据,使用户和应用程序能够方便地存储、访问和组织文件和目录。
总结
分区表是描述磁盘上分区布局的信息表,用于记录每个分区的位置和大小。
文件系统是位于某个分区内的结构,用于管理该分区中的文件和数据。
分区表和文件系统是磁盘管理中的两个不同层次,分区表位于磁盘的全局层次,定义了磁盘的分区布局;而文件系统位于分区内,管理该分区中的数据。
内核负责加载文件系统吗
是的,内核负责加载文件系统。具体来说,操作系统的内核负责识别和挂载文件系统,使得存储设备上的数据可以被操作系统和应用程序访问。
文件系统加载的过程
- 设备识别: 当系统启动或插入一个新的存储设备(如硬盘、USB设备)时,内核会识别出该设备并读取其分区表。通过分区表,内核能够了解设备上存在的分区及其位置。
- 识别文件系统类型: 内核根据分区表信息识别每个分区上使用的文件系统类型。例如,分区可能使用ext4、NTFS、FAT32等文件系统。内核通过读取分区上的超级块等元数据来确定文件系统类型。
- 加载文件系统驱动程序: 内核加载相应的文件系统驱动程序(也称为文件系统模块),该驱动程序负责与特定类型的文件系统进行交互。例如,加载ext4文件系统时,内核会使用ext4驱动程序。
- 挂载文件系统: 在加载了文件系统驱动程序之后,内核将文件系统挂载到系统的目录树中。挂载点是一个目录,所有挂载的文件系统的内容都会显示在该目录下。挂载操作可以是手动执行的(通过mount命令)或者自动执行的(如在启动时根据/etc/fstab文件进行自动挂载)。
- 挂载后,用户和应用程序可以通过挂载点访问文件系统上的文件和目录。
文件系统管理
一旦文件系统被挂载,内核继续管理文件系统中的文件操作,包括文件的创建、读取、写入、删除等。这些操作通过系统调用(如open、read、write等)与内核进行交互,由内核处理并最终与文件系统驱动程序通信。
内核与文件系统的关系
- 文件系统驱动:内核中包含多个文件系统驱动程序,每个驱动程序负责处理特定类型的文件系统。当内核识别出某个文件系统类型时,它会加载对应的驱动程序来进行处理。
- 虚拟文件系统 (VFS):内核还包含一个虚拟文件系统层(VFS),这是一个抽象层,它提供了一种通用接口,使得不同类型的文件系统可以以一致的方式被操作系统管理和访问。
- 挂载管理:内核管理文件系统的挂载点,并确保挂载点的唯一性和正确性,防止同一目录下挂载多个文件系统导致的冲突。
总结
内核确实负责加载文件系统,它识别设备上的文件系统类型,加载相应的驱动程序,并将文件系统挂载到操作系统的目录树中,使其可以被操作系统和用户访问和管理。
当应用程序执行一个系统调用创建一个文件,是内核负责维护文件系统的内容,还是文件系统驱动程序负责
当应用程序执行一个系统调用(例如open、write、create等)来创建一个文件时,整个过程是由操作系统的内核来管理的,其中包括与文件系统驱动程序的交互。
系统调用处理: 当应用程序发起一个系统调用来创建文件时,这个请求首先被发送到内核。内核通过系统调用接口(系统调用表)接收到请求,并根据请求类型将其路由到适当的内核模块。
虚拟文件系统 (VFS) 层: 内核中的虚拟文件系统(VFS)层是一个抽象层,它为不同的文件系统提供了统一的接口。VFS负责处理与文件系统相关的所有操作请求,并将这些请求转换为与具体文件系统类型相关的操作。VFS管理文件系统的挂载点、目录结构、文件描述符等,并将文件操作映射到正确的文件系统驱动程序。
文件系统驱动程序: 文件系统驱动程序是内核的一部分,它实现了与特定文件系统类型(如ext4、NTFS、XFS等)相关的所有底层操作。文件系统驱动程序负责处理VFS层传递下来的请求。在文件创建过程中,驱动程序会执行以下操作:在文件系统的元数据中分配一个新的索引节点(inode)来表示新文件。更新目录结构,将新文件的名称和inode关联起来。分配数据块,用于存储文件的内容,并将这些块与文件的inode关联。更新文件系统的元数据,如超级块和位图,以反映新文件的创建。
硬件与存储设备: 最后,文件系统驱动程序与内核的存储子系统交互,将文件系统的变化写入实际的存储设备(如硬盘、SSD)。存储子系统负责将这些请求转换为具体的磁盘操作,如读写数据块。
责任划分总结:内核的责任: 处理系统调用请求,管理系统资源。通过VFS层为不同类型的文件系统提供统一接口。协调不同文件系统驱动程序的工作。
文件系统驱动程序的责任: 实现具体的文件系统操作逻辑,如文件创建、删除、读取、写入等。管理与文件系统相关的元数据和数据块。因此,当应用程序执行系统调用创建文件时,内核负责总体的协调和管理工作,包括接收系统调用、通过VFS层处理请求;文件系统驱动程序则负责具体的文件系统操作,包括分配inode、更新目录结构和写入数据等。这两者共同协作,确保文件系统的内容被正确维护。
存储子系统一般是什么
存储子系统是操作系统中负责管理和协调存储设备(如硬盘、固态硬盘、光盘、网络存储等)与操作系统之间的交互的组件。它在操作系统和硬件之间起到桥梁作用,确保数据能够高效、安全地存储和访问。
存储子系统的主要组成部分
- 存储设备驱动程序: 存储设备驱动程序负责与具体的物理存储设备通信。这些驱动程序了解设备的硬件特性,并通过相应的接口(如SATA、NVMe、SCSI等)进行数据传输和管理。驱动程序将文件系统请求转换为设备特定的读写操作。例如,将文件系统层的块操作转换为磁盘的扇区读写命令。
- I/O 调度器 (I/O Scheduler): I/O调度器是存储子系统中的一个重要组件,它决定了存储设备上I/O操作的执行顺序。调度器的任务是优化I/O操作的顺序,以提高磁盘性能、减少延迟和提高系统吞吐量。常见的调度算法有完全公平队列 (CFQ)、Deadline、Noop等。不同的调度算法在不同的工作负载下表现不同。
- 缓存与缓冲管理: 操作系统通常会使用内存中的缓存(如页面缓存)来加速存储设备的访问。缓存保存最近访问的数据块或即将写入的数据块,从而减少对慢速存储设备的直接访问频率。缓冲管理确保数据在从内存到存储设备之间传输时,能够得到有效的处理,例如通过合并多个写操作或延迟写入来提高效率。
- 存储虚拟化层: 存储虚拟化是存储子系统中的一个高级功能,用于将多个物理存储设备抽象为一个或多个逻辑存储设备。RAID(独立磁盘冗余阵列)是存储虚拟化的一个常见例子,提供了数据冗余和性能增强。逻辑卷管理器 (LVM) 也是存储虚拟化的一种形式,允许管理员灵活地管理物理存储设备上的卷。
- 文件系统接口: 存储子系统为文件系统提供底层支持。文件系统依赖存储子系统来执行物理设备上的读写操作、数据块分配、设备管理等功能。通过存储子系统,文件系统可以在底层设备之间进行无缝的数据操作,而不必关心具体的硬件细节。
- 多路径I/O (Multipath I/O): 多路径I/O技术允许一个存储设备通过多个物理路径连接到系统。这样,当某条路径发生故障时,I/O操作可以通过备用路径继续进行,提高了系统的可靠性和可用性。
- 卷管理器: 卷管理器(如LVM)提供了在多个物理磁盘上创建和管理逻辑卷的功能。这使得管理员可以动态调整存储容量,进行快照、复制等操作,而不必直接操作物理磁盘。
存储子系统的作用
- 数据传输管理: 它管理数据在内存和存储设备之间的传输,确保数据正确写入磁盘或从磁盘读取。
- 性能优化: 通过缓存、I/O调度等机制,存储子系统优化了存储设备的访问速度,提高了整体系统性能。
- 设备抽象: 存储子系统将底层复杂的存储硬件抽象为简单的接口,供文件系统和应用程序使用。
- 可靠性与冗余: 存储子系统通过多路径I/O、RAID、快照等技术,提供了数据冗余和故障恢复能力,提高了系统的可靠性。
总结
存储子系统是操作系统中用于管理和优化存储设备的关键组件。它包括了驱动程序、I/O调度器、缓存、存储虚拟化、卷管理器等模块,确保存储设备的高效、安全使用,并为文件系统和应用程序提供统一的接口来访问底层存储资源。
文件系统类型
Linux 文件系统支持包括针对 Linux 原生设计优化的文件系统,外部文件系统,比如 Windows 的 FAT 系列,universal filesystems 比如 ISO 9660。
- The Fourth Extended filesystem ext4
- Btrfs B-tree filesystem
- FAT filesystems(msdos、vfat、exfat)
- XFS
- HFS+ apple standard used on most Mac
- ISO 9660 CD-ROM standard
怎么查看文件系统类型
df -Tlsblk -fblkid/etc/fstabmount | grep "^/dev"
创建文件系统
对一个新的块设备,在分区完成后,就要创建一个文件系统,可以使用 mkfs,可以创建许多类型的文件系统。
mkfs -t ext4 /dev/sdf2。mkfs 工具自动决定一个设备上的 blocks 数量并且设置许多合理的默认值,除非非常熟悉这些参数,否则不要轻易修改。
注意
文件系统创建是一项只有在添加新磁盘或对旧磁盘重新分区后才应执行的任务。应该为每个没有预先存在的数据(或包含要删除的数据)的新分区创建一次文件系统。在现有文件系统之上创建新的文件系统将有效地销毁旧数据。
mkfs 是一个前端工具,ls -l /sbin/mkfs*。会根据参数自动调用后端的工具。
挂载文件系统
要挂载一个文件系统,必须知道以下几点:
- 文件系统的块设备、位置和标志符,某些特殊目的的文件系统没有位置,比如 proc 和 sysfs。
- 文件系统的类型
- 挂载点,挂载点通常是一个目录,可以在任意目录下,不必在
/目录下。
对于挂载文件系统的通用术语是 mount a device/分区设备 on a mount point。可以使用 mount 查看当前挂载情况。
mount 输出的每一行都对应当前挂载的一个文件系统:
- 设备,注意某些并不是真实的设备(如 proc),这里用 proc 代表设备名称,其实这些特殊的文件系统并不要具体的设备
- on
- mount point
- type
- filesystem type
- mount options
取消挂载:unmount mountpoint。
注意:几乎所有 Linux 系统都包含一个临时挂载点 /mnt,通常用于测试。在进行试验时可以随意使用它,但如果打算挂载文件系统以供扩展使用,请找到或创建另一个位置。
Filesystem UUID
上面挂载文件系统是使用设备名称的,然后设备名称是会变的,设备名称取决于内核发现它们的顺序,要解决这个问题,可以使用设备的 UUID 来识别和挂载文件系统。文件系统创建工具在创建文件系统的时候会自动设置一个 UUID。要查看设备和对应的 UUID 可以使用 blkid。
使用 UUID 挂载文件系统 mount UUID=b600fe63-d2e9-461c-a5cd-d3b373a5e1d2 /home/extra。
通常,一般不会像这样通过 UUID 手动挂载文件系统,因为我们通常知道该设备,并且通过名称挂载设备比通过其疯狂的 UUID 挂载要容易得多。尽管如此,了解 UUID 仍然很重要。一方面,它们是在启动时自动在 /etc/fstab 中挂载非 LVM 文件系统的首选方式。此外,许多发行版在插入可移动介质时使用 UUID 作为安装点。
文件系统的 UUID 是可以改的。
为什么说是挂载文件系统而不是挂载块设备呢
在 Linux 系统中,之所以说挂载文件系统而不是挂载块设备,是因为块设备(如硬盘分区)只是存储数据的物理设备,而文件系统则是管理这些数据的逻辑结构。挂载的过程是将文件系统关联到操作系统的目录树中,以便用户和应用程序可以通过文件路径访问存储在块设备上的数据。
以下是具体原因:
- 块设备是物理存储,文件系统是数据的逻辑管理方式
块设备(如 /dev/sda1)是底层的物理存储设备,它只是存储原始数据块,不能直接用于存取文件数据。
文件系统(如 ext4、xfs、btrfs 等)是用于组织和管理这些数据的逻辑结构,它提供了一种抽象层,让操作系统可以理解和管理数据,并通过文件和目录的形式呈现出来。 - 挂载是将文件系统映射到目录树中
挂载的实际操作是将某个设备上的文件系统关联到操作系统的目录树中的一个目录(挂载点),使得操作系统能够通过该目录来访问文件和目录。
你不能直接将一个块设备挂载到目录树上,因为块设备本身没有组织数据的逻辑,需要文件系统的帮助来解释这些数据块。 - 文件系统提供文件访问接口
文件系统提供了具体的文件读写、权限管理、目录结构等操作。这些是用户和应用程序所需的功能。挂载文件系统后,用户可以通过路径访问、管理文件,而不需要关心块设备的底层结构。
如果没有文件系统,即使你可以访问块设备上的原始数据,它也只是无序的数据块,无法方便地读取或管理。 - 块设备可以有多个分区和文件系统
一个块设备可以有多个分区,每个分区可能使用不同的文件系统。每次挂载时,你实际上是选择挂载某个分区中的文件系统,而不是整个块设备。通过挂载特定的文件系统,操作系统可以正确解析其中的数据。
例如,设备 /dev/sda 可能有多个分区 /dev/sda1, /dev/sda2,每个分区可能有不同的文件系统(例如 /dev/sda1 是 ext4,/dev/sda2 是 xfs),挂载时分别挂载这些文件系统。 - 未格式化的块设备不能挂载
如果一个块设备未被格式化(即没有文件系统),它是不能被挂载的,因为挂载的对象是文件系统。未格式化的块设备只是一系列原始的数据块,操作系统无法理解或访问其中的数据。
总结:挂载文件系统而不是块设备的核心原因是:块设备只是存储数据的物理设备,而文件系统负责组织和管理这些数据。挂载的过程实际上是将设备上的文件系统关联到操作系统的目录结构中,从而使用户能够通过文件和目录的方式访问存储在块设备上的数据。
文件系统需要挂载那块设备是什么时候被识别的呢
块设备通常在以下情况下被系统识别:
- 系统启动时
当计算机启动时,内核会扫描所有连接到系统的硬件设备,包括硬盘、SSD、USB 驱动器等块设备。系统会自动识别这些设备并为它们分配对应的设备文件(如 /dev/sda、/dev/sdb 等)。 - 设备插入时
如果在系统运行时插入一个新的块设备(例如插入 USB 驱动器、外接硬盘),内核会通过 udev 设备管理守护进程自动检测设备的插入,并创建相应的设备文件。 - 加载驱动程序时
如果系统中的某些块设备需要特定的驱动程序,只有当该驱动程序被加载后,内核才会识别出该设备。例如,某些 RAID 控制器或外部存储设备在加载相应驱动后才被系统识别。 - 热插拔支持
对于支持热插拔(Hot Plug)的设备,例如 USB 设备或部分 SATA 硬盘,内核能够在设备插入时立即检测并识别。
一旦块设备被系统识别后,它们会以 /dev 目录中的设备文件形式出现,允许用户和应用程序通过文件系统访问这些设备。
Disk Buffering Caching and Filesystems
就像需要其他 Unix 变种一样,Linux buffers writes to the disk,Linux 把写磁盘的操作缓存起来,并不立即写磁盘。This means the kernel usually doesn’t immediately write changes to filesystems when processes request changes。相反,它把这些 changes 存在 RAM 中直到内核决定了一个好的时间来真正把这些数据写到磁盘上,这个 buffering system 对用户来说是透明的并且获得了巨大的性能提示。
当 unmount 一个文件系统时,内核自动 synchronizes with disk,writing the changes in its buffer to the disk,也可以手动执行同步,sync命令默认同步系统上所有的磁盘。
In addition, the kernel uses RAM to cache blocks as they’re read from a disk. Therefore, if one or more processes repeatedly access a file, the kernel doesn’t have to go to the disk again and again—it can simply read from the cache and save time and resources。
Filesystem Mount Options
mount 选项太多了,这里介绍几个有用的。选项大致分为两类:general and filesystem-specific。general 选项适用于所有文件系统,filesystem-specific 选项适用于特定的文件系统。要激活文件系统选项,使用 -o 开关,后跟该选项。例如,-o remount,rw 重新挂载已在读写模式下以只读方式挂载的文件系统。
Short General Options
通用选项通常是短的语法,最重要的几个:
-r以只读方式挂载文件系统,这个选项有许多用途,从 write protection 到 bootstrapping,想使用只读设备时(CD-ROM)不需要指定,系统会自动帮助设置-nThe -n option ensures that mount does not try to update the system runtime mount database, /etc/mtab. By default, the mount operation fails when it cannot write to this file, so this option is important at boot time because the root partition (including the system mount database) is read-only at first. You’ll also find this option handy when trying to fix a system problem in single-user mode, because the system mount database may not be available at the time.-t指定文件系统类型
Long Options
要使用长选项,在 -o 后面跟用逗号分割的若干选项。mount -t vfat /dev/sde1 /dos -o ro,uid=1000
常使用的长选项:
- exec、noexec 允许或禁止在文件系统上执行程序
- suid、nosuid 允许或禁止 setuid 程序
- ro 以只读方式挂载文件系统
- rw 以读写模式挂载文件系统
Remounting a Filesystem
有时需要修改已经挂载的文件系统的选项参数,此时需要重新挂载文件系统。
The /etc/fstab Filesystem Table
要在系统引导时自动挂载文件系统并从枯燥的手动挂载中解放出来,Linux 在 /etc/fstab 中维护了自动挂载的文件系统的信息。
每一行对应一个文件系统,可以分为六个字段:
- The device or UUID
- The mount point
- The filesystem type
- Options long options separated by commas
- Backup information for use by the dump(过时的命令) commad 一般都设置为 0
- The filesystem integrity test order fsck 检查文件系统的顺序
1 | UUID=70ccd6e7-6ae6-44f6-812c-51aab8036d29 / ext4 errors=remount-ro 0 1 |
上面的例子引入了一些新的选项 errors、noauto、user,这些选项不适用于 /etc/fstab 之外,此外经常看到 defaults 选项,这些选项的定义是:
- defaults 设置了 mount 的默认值,比如:read-write mode、enable device files、executables 等,使用 defaults 可以让
/etc/fstab更优雅 - errors 特定于 ext2/3/4 文件系统的选项,在系统挂载出现问题时设置内核的行为,默认是
errors=continue,这意味着内核应该返回一个错误并且继续运行。要让内核以只读模式重新尝试挂载可以使用errors=remount-ro,errors=panic设置告诉内核当挂载出现问题时执行 halt。 - noauto 这个选项告诉
mount -a命令忽略这个文件系统 - user 此选项允许非特权用户在特定条目上运行挂载,这对于允许对可移动媒体进行某些类型的访问非常方便。由于用户可以将 setuid-root 文件放在另一个系统的可移动介质上,因此此选项还会设置 nosuid、noexec 和 nodev(以禁止特殊设备文件)。记住,对于可移动媒体和其他一般情况,此选项现在的用途有限,因为大多数系统使用 ubus 以及其他机制来自动安装插入的媒体。但是,当想要授予对安装特定目录的控制权时,此选项在特殊情况下很有用。
/etc/fstab 的替代品
虽然 /etc/fstab 文件已经成了传统的表现文件系统和它的挂载点的方式,但是也有其他两个的选择。
/etc/fstab.d该目录包含若干文件,一个文件代表一个文件系统- 第二个选择就是配置 systemd units 文件,这个文件一般是从
/etc/fstab生成的
文件系统的容量
要查看当前挂载的文件系统的容量和使用情况可以使用 df 命令。其输出如下:
- Filesystem The filesystem device
- 1k-blocks The total capacity of the filesystem in blocks of 1024 bytes
- Used The number of occupied blocks
- Available The number of free blocks
- Use% The percentage of blocks in use
- Mounted on The mount point
从 df 输出上可以看到,已使用的和可用的加起来并不等于总容量,并且百分比也相差 5%,在这两种情况下,总容量的 5% 下落不明。事实上,空间就在那里,但它隐藏在保留块中。当文件系统开始填满时,只有超级用户才能使用文件系统的保留块。此功能可以防止系统服务器在磁盘空间不足时立即出现故障。
注意
POSIX 标准定义一个块的大小是 512 字节,然而这个数字很难读,所以默认情况下 df 和 du 命令在大多数的 Linux 发行版中都使用 1024-bytes blocks,如果实在想要用 512-bytes 显示,可以配置环境变量 export POSIXLY_CORRECT=1,这里会用 512B-blocks 显示,df -k会用 1K-blocks 显示,-m 选项以 1MB-blocks 显示。
Checking and Repairing Filesystems
Unix 文件系统提供的优化是通过复杂的数据库机制实现的。为了使文件系统无缝工作,内核必须相信已安装的文件系统没有错误,并且硬件可靠地存储数据。如果存在错误,可能会导致数据丢失和系统崩溃。
除了硬件上问题之外,文件系统的问题通常是由用户粗鲁的关闭系统导致的,在这种情况下,内存中先前的文件系统缓存可能与磁盘上的数据不匹配,并且当碰巧粗鲁的关闭计算机时,系统也可能正在更改文件系统。尽管许多文件系统支持日志机制,使文件系统损坏的情况大大减少,但应该始终正确关闭系统。
无论使用什么文件系统,仍然需要时不时地检查文件系统,以确保一切都正常。
检查文件系统的工具是 fsck,就像 mkfs 一样,fsck 也有针对不同文件系统的很多版本,通常会自己判断文件系统类型,并正确的调用对应的文件系统检查工具。
细节:略。
特殊用途的文件系统
并非所有文件系统都代表物理介质上的存储。大多数版本的 Unix 都有充当系统接口的文件系统。也就是说,文件系统不仅可以作为在设备上存储数据的手段,还可以表示系统信息,例如进程 ID 和内核诊断信息。
特殊的文件系统:
- proc mounted on /proc proc 是 process 的缩写,这个目录下的每个数字目录代表一个系统上正在运行的进程,数字目录底下的文件代表了进程的若干信息。Linux proc 文件系统在
/proc/cpuinfo等文件中包含大量附加内核和硬件信息。请记住,内核设计指南建议将与进程无关的信息从/proc移出并移入/sys,因此/proc中的系统信息可能不是最新的接口。 - sysfs mounted on /sys
- tmpfs mounted on /run or other locations 有了 tmpfs 后,可以使用物理内存和 swap space 作为临时存储,You can mount tmpfs where you like, using the
sizeandnr_blockslong options to control the maximum size。但是,请小心不要不断地将东西放入tmpfs位置,因为系统最终会耗尽内存,程序将开始崩溃。 - overlay A filesystem that merges directories into a composite. 容器一般使用 overlay 文件系统。
Swap Space
并不是磁盘上每个分区都有一个文件系统。还可以用磁盘空间来增加机器上的 RAM。如果实际内存不足,Linux 虚拟内存系统可以自动将内存片段移入磁盘存储或从磁盘存储移出。这称为交换,因为空闲程序片段被交换到磁盘,以换取驻留在磁盘上的活动片段。用于存储内存页的磁盘区域称为交换空间(或简称交换)。
使用磁盘分区作为交互空间
- 确保磁盘分区是空的。
- 运行
mkswap dev,dev 是分区的名称。这个命令会在分区上打上一个swap signature,标记分区为一个 swap space。 - 执行
swapon dev,注册交互空间到内核上。
创建完交换分区后,可以在 /etc/fstab 中添加项目,以便系统启动时自动使用交换分区。/dev/sda5 none swap sw 0 0,Swap signature 也有 UUIDS。记住许多系统现在都使用 UUID 而不是设备名称。
使用文件作为交换空间
如果不想重新分区磁盘以创建交换分区,则可以使用常规文件作为交换空间。
Use these commands to create an empty file, initialize it as swap, and add it to the swap pool:
1 | dd if=/dev/zero of=swap_file bs=1024k count=num_mb |
这里的 swap_file 就是建行文件的名称。
如果想从内核的 active pool 中移除交换分区可以使用 swapoff 命令。系统必须有足够的可用剩余内存(实际内存和交换内存组合)来容纳要删除的交换池(swap pool)部分中的任何活动页面。
需要多少交换空间
曾经,Unix 传统观点认为,应该始终保留至少两倍于实际内存的交换空间。如今,不仅可用的巨大磁盘和内存容量使问题变得模糊,而且我们使用系统的方式也使问题变得模糊。一方面,磁盘空间非常充足,因此很容易分配两倍以上的内存大小。另一方面,可能永远不会使用你的交换空间,因为有很多的真实内存。
双倍实际内存”规则源自多个用户登录到一台计算机的时代。不过,并非所有用户都处于活动状态,因此当活动用户需要更多内存时,能够方便地交换不活动用户的内存。
对于单用户机器来说,同样的情况可能仍然适用。如果正在运行许多进程,通常可以交换部分不活动进程,甚至交换活动进程的不活动部分。然而,如果因为许多活动进程想要同时使用内存而频繁访问交换空间,那么将遭受严重的性能问题,因为磁盘 I/O(甚至 SSD 的 I/O)速度太慢,无法跟上其余进程的速度。唯一的解决方案是购买更多内存、终止某些进程或抱怨。
有时,Linux 内核可能会选择交换进程以支持更多的磁盘缓存。为了防止这种行为,一些管理员将某些系统配置为根本没有交换空间。例如,高性能服务器永远不应该占用交换空间,并且应该尽可能避免磁盘访问。
在通用机器上不配置交换空间是危险的。如果一台机器完全耗尽了实际内存和交换空间,Linux 内核会调用内存不足 (OOM) killer 来终止进程以释放一些内存。显然不希望桌面应用程序发生这种情况。另一方面,高性能服务器包括复杂的监控、冗余和负载平衡系统,以确保它们永远不会到达危险区域。
LVM
略
向前看:磁盘和用户空间
In disk-related components on a Unix system, the boundaries between user space and the kernel can be difficult to characterize. As you’ve seen, the kernel handles raw block I/O from the devices, and user-space tools can use the block I/O through device files. However, user space typically uses the block I/O only for initializing operations, such as partitioning, filesystem creation, and swap space creation. In normal use, user space uses only the filesystem support that the kernel provides on top of the block I/O. Similarly, the kernel also handles most of the tedious details when dealing with swap space in the virtual memory system.
传统文件系统的内部
传统的 Unix 文件系统有两个主要的组件:a pool of data blocks where you can store data and a database system that manages the data pool。数据块和管理数据块的数据结构。
数据库以索引节点数据结构(inodes)为中心。一个 inode 是一组描述一个特定文件的数据,包括文件的类型、权限和(或许是最重要的部分)文件数据存在哪个data pool 中。
Inodes 由 inodes table 中列出的数字来标识。
Filenames and directories are also implemented as inodes.
A directory inode contains a list of filenames and links corresponding to other inodes。
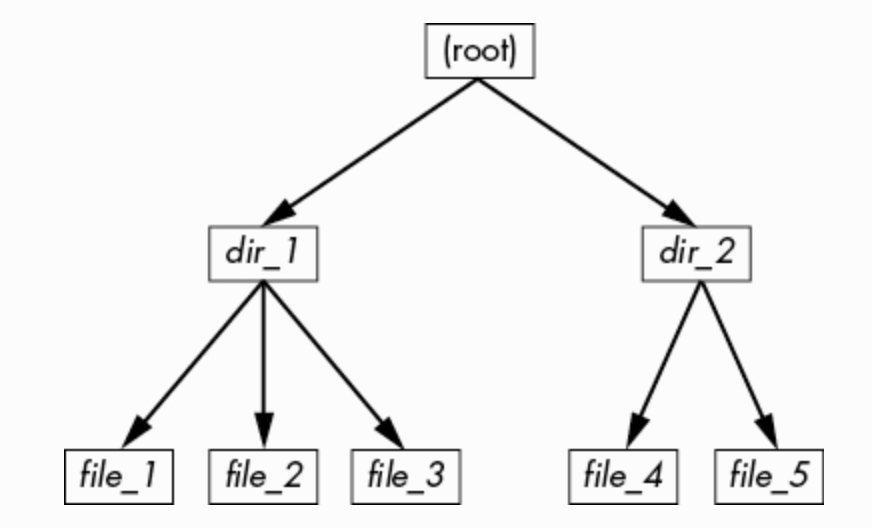
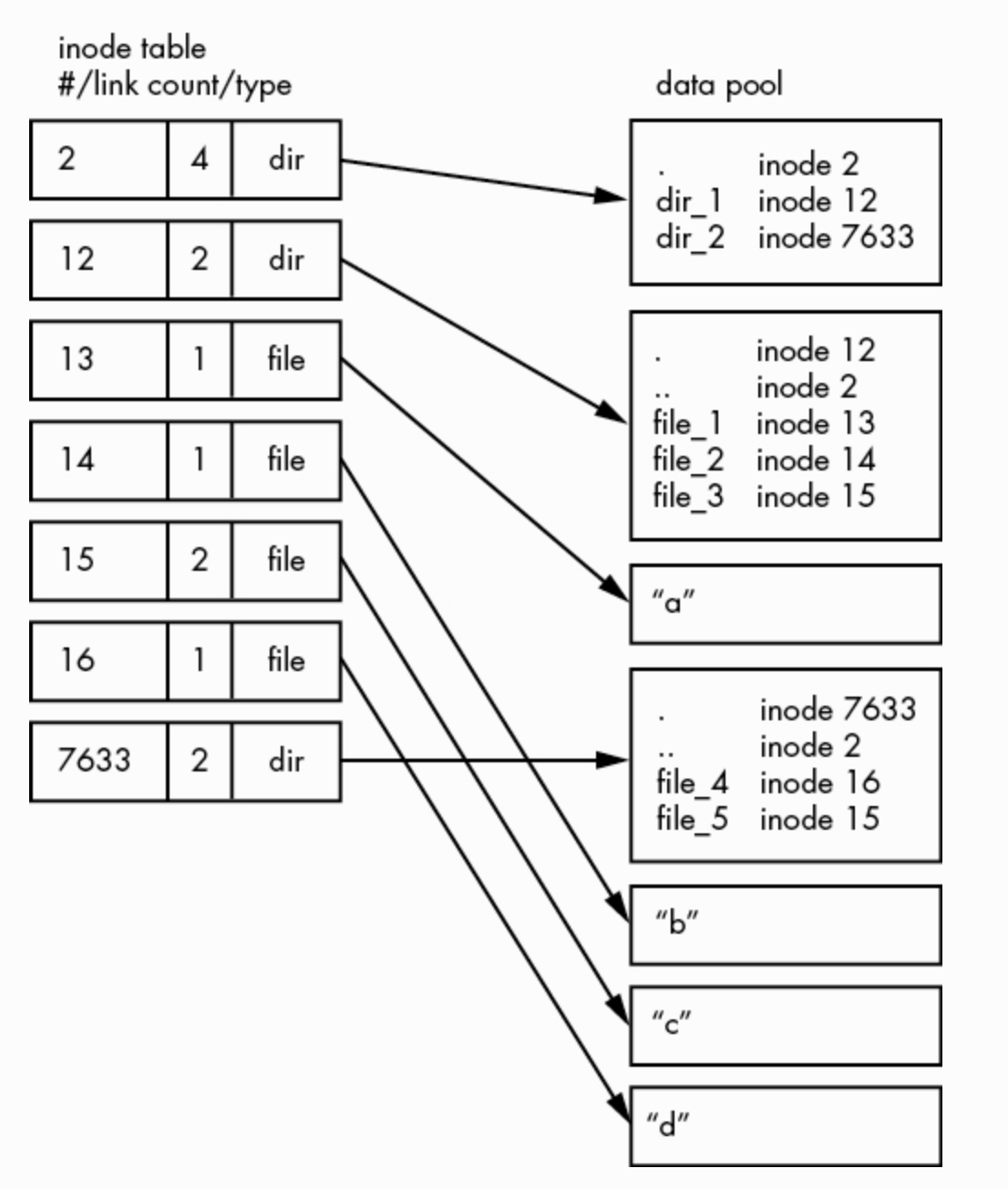
怎么理解?对于任何 ext2/3/4 文件系统,inode number 从 2 开始,也就是 root inode,不要和 system root filesystem 搞混淆,从 inode 为 2 的节点可以看出它是一个目录,并能找到它关联的 data pool,从中可以看到 root directory 的内容,dir_1 inode=12 和 dir_2 inode=7633。
当查找一个文件时,时内核负责还是文件系统负责找?内核负责管理文件系统,并把用户请求通过 VFS 层转发给文件系统,文件系统负责找。
Inode details and the link count
ls -i 查看 inode 号。2 号 inode 的 link count 是 4,其中一个是 superblock 的引用,一个是 .,还有两个是两个子目录中的 ..。
Block Allocation
在给一个新文件分配 data pool blocks 时,文件系统怎么知道哪些块被使用了,哪些没有被使用呢?其中一个最基本的方式就是使用额外的管理数据结构:a block bitmap。在这种模式下,文件系统保留了一系列的字节,这些字节中的每一个位代表 data pool 中的一个 block。